

The term neighbor usually evokes pleasant thoughts like a young family playing in a sprinkler or the elderly couple who still walks a freshly baked apple pie through the back yard in the fall. Within the insurance industry, however, a neighbor can be one of the biggest challenges when considering co-tenant and adjacent risk management in insurance. The café next door is super convenient for a midday snack, but a problem in the kitchen can be big trouble for many. Sometimes bad apples are the concern. One business’ customer is another’s bane, bringing undesirable behavior like graffiti or theft.
Historically, the “greater we” have relied on primitive approaches to identify these types of risks near our insured. Recently, however, technologies like 3D surface models, computer vision, and best-of-breed data offerings provide us with the tools required to answer these questions with accuracy, precision, and transparency.
Identifying co-tenant and adjacent risk: “Old school” techniques miss important details
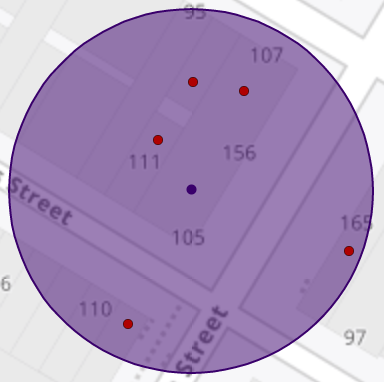
We’ve been using the same technique for decades when considering co-tenant and adjacent risk management for insurance. Given an address, drop a pin on the ground, draw a circle and return all other businesses that operate within that radius. Sounds easy, right?
This approach is better than doing nothing, sure, but it’s fraught with error. Representing a business as a point is a gross over-simplification of reality. The settings in which we live and work can be simple, like a single-family home, or complex like a multi-building commercial complex. In either case, a singular point is just an approximation of something larger. The trickle-down is that we’re performing a precise operation vs. imprecise inputs, making it somewhat arbitrary. The only guaranteed result of this combination is a lack of confidence.
Read the Forbes Insights report
Close Enough is Not Good Enough: Why Hyper-Accurate Location Data Matters for Insurance
Learn why a “close enough is good enough” approach to location in premium pricing overlooks the importance of accuracy—and as a consequence, opens up insurers to underpricing risk and adverse selection.
False positives appear when the radius picks up a business that is not a co-tenant or even adjacent. It could be clear across the street. Hopefully we don’t lose this policy unnecessarily.
False negatives are likely worse. Imagine a strip setting. Your search radius is 150 feet, but the dry cleaner at the end is 175ft. Are those nasty chemicals in the same building as your insured? They very well may be.
Advancements in mapping and location data lead to more mature processes for risk management in insurance
The key to any great recipe is the proper ingredients. The key ingredients to this risk solution are parcel boundaries and building footprints.

Parcel boundaries represent the real property for a particular location. Most often they represent land, but sometimes are buildings, whole or partial, for example a townhome or condominium. This data is sourced primarily from local jurisdictions like counties. There is no magic to the improvements here; it has just gotten better over time.
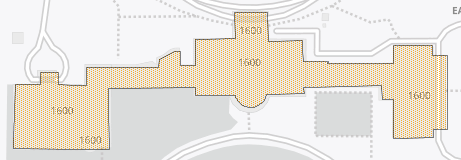
Building footprints came into vogue in 2018 when Microsoft released an open U.S.-wide vector building dataset. It wasn’t supreme quality but made it obvious to most the value of accurate representations of a structure, not just an approximation.
Developments in related technologies continue to press the envelope and building products have reaped the benefits. They are significantly more detailed than early versions. Advancements in imagery have provided a better picture of the world we live in. 3D surface models of earth help detect changes in elevation, including buildings. Computer vision is a field of artificial intelligence that trains computers to interpret visual evidence. In other words, we’ve taught a computer how to find buildings in a picture. This is pretty awesome stuff.

As parcels and buildings have improved, so have derived products such as geocoding datasets. This means that address locations are more accurate than ever and likely indicate the exact building that contains the address. If we can place an address inside a building, then we can place a business there as well.
Shameless plug: In February ‘21, Precisely released a groundbreaking version of its Master Location Data (MLD) geocoding solution which places 80% of all addresses in the United States on a building.
“New school” techniques use parcels and building footprints to more accurately identify co-tenant and adjacent risk
Since we define co-tenancy as being in the same building or on the same property and adjacency as “next door,” we should leverage those concepts in our risk management for insurance solution. We’re able to get rid of that old point-and-circle technique and implement something closer to reality.
Here’s what it looks like. Given an address, we identify both building and property. A secondary search identifies adjacent and proximal buildings. Now instead of the radius, we use these geographies to identify businesses within and flag them as being respectively in the same building, adjacent to, or on the same property.
This technique is both more precise and discrete, meaning more confidence in our business decisions. Knowing that a risk is in the same building could be quite different from an adjacent one. This level of transparency is really what we are after. Much better than approximate and arbitrary.
To learn why a “close enough is good enough” approach to location in premium pricing overlooks the importance of accuracy—and as a consequence, opens up insurers to underpricing risk and adverse selection, read this Forbes Insights white paper: Close Enough is Not Good Enough – Why Hyper-Accurate Location Data Matters for Insurance.




