

The concept of streaming data was born of necessity. Today’s hypercompetitive global business environment calls for agility and intelligence. More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. But insights derived from day-old data don’t cut it. Many scenarios call for up-to-the-minute information.
Enterprise technology is having a watershed moment; no longer do we access information once a week, or even once a day. Now, information is dynamic. Business success is based on how we use continuously changing data.
That’s where streaming data pipelines come into play. This article explores what streaming data pipelines are, how they work, and how to build this data pipeline architecture.
What is a streaming data pipeline?
A data pipeline is software that enables the smooth, automated flow of information from one point to another, virtually in real time. This software prevents many of the common problems that the enterprise experiences: information corruption, bottlenecks, conflict between data sources, and the generation of duplicate entries.
Streaming data pipelines, by extension, offer an architecture capable of handling large volumes of data, accommodating millions of events in near real time. That enables you to collect, analyze, and store large amounts of information. It also allows for applications, analytics, and reporting to process information as it happens.
How do streaming data pipelines work?
The first step in a streaming data pipeline is where information enters the pipeline. One very popular platform is Apache Kafka, a powerful open-source tool used by thousands of companies. But in all likelihood, Kafka doesn’t natively connect with the applications that contain your data. You need a separate tool to do that.
Change data capture (CDC) software provides the missing link. In a nutshell, CDC software mines the information stored in database logs and sends it to a streaming event handler like Kafka. When someone creates a new record in the source application or makes a change to an existing record, that activity is recorded in the database log. CDC software uses that information as its raw material. Then it transforms the format and/or content of that data before sending it on its way.
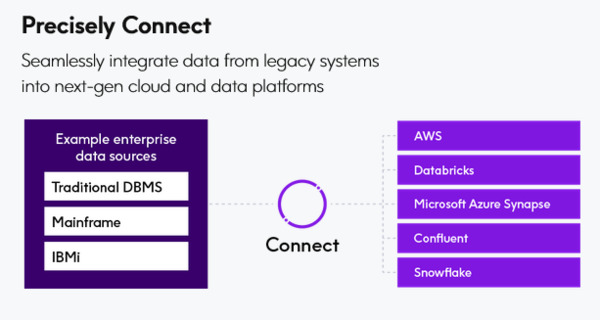
Eventually, your streaming data pipeline delivers the information to its final destination. In many cases, that will be a cloud-based analytics platform like Snowflake, Databricks, or Amazon Redshift for real-time insights.
Many organizations use streaming data pipelines with tools like Splunk, ServiceNow, or other SIEM software to monitor and analyze IT events in real time. Others use it to detect anomalies in financial transactions, monitor operational systems for potential problems, or gather up-to-the-minute feedback on supply chain logistics.
The streaming data pipeline connects to an analytics engine that lets you analyze information. You can also share the information with colleagues so that they too can answer (and start to address) business questions.
Read our eBook
A Data Integrator’s Guide to Successful Big Data Projects
This eBook will guide through the ins and outs of building successful big data projects on a solid foundation of data integration.
Building a real-time data pipeline architecture
To build a streaming data pipeline, you’ll need a few tools.
First, you’ll require an in-memory framework (such as Spark), which handles batch, real-time analytics, and data processing workloads. You’ll also need a streaming platform (Kafka is a popular choice, but there are others on the market) to build the streaming data pipeline. In addition, you’ll also need a NoSQL database (many people use HBase, but you have a variety of choices available).
Before building the streaming data pipeline, you’ll need to transform, cleanse, validate, and write the data to make sure that it’s in the right format and that it’s useful. To build the streaming data pipeline, you’ll initialize the in-memory framework. Then, you’ll initialize the streaming context.
Step three is to fetch the data from the streaming platform. Next, you’ll transform the data. The fifth step is to manage the pipeline to ensure everything is working as intended.
Streaming data pipelines represent a new frontier in business technology, one that allows you to maintain a competitive advantage and analyze large amounts of information in real time. The right tools enable you to build and maintain your streaming data pipeline and assure data accessibility across the enterprise.
The fastest path to creating, deploying, and managing streaming data pipelines is a robust change data capture products like the Data Integration Service from Precisely. Precisely Connect enables you to take control of your data, integrating through batch or real-time ingestion to reliably deliver data for advanced analytics, comprehensive machine learning, and seamless data migration.
Interested in learning more about streaming data pipelines for your organization? If so, check out our eBook: A Data Integrator’s Guide to Successful Big Data Projects.




