

To a layperson, data verification and data validation may sound like the same thing. When you delve into the intricacies of data quality, however, these two important pieces of the puzzle are distinctly different. Knowing the distinction can help you to better understand the bigger picture of data quality.
What Is Data Validation?
In a nutshell, data validation is the process of determining whether a particular piece of information falls within the acceptable range of values for a given field.
In the United States, for example, every street address should include a distinct field for the state. Certain values such as NH, ND, AK, and TX conform to the list of state abbreviations as defined by the U.S. Postal Service. As you know, those abbreviations denote specific states.
There are also two-character abbreviations for U.S. territories, such as Guam (“GU”) and the Northern Mariana Islands (“MP”). If you were to enter “ZP” or “A7” in the state field, you would, in essence, be invalidating the entire address, because no such state or territory exists. Data validation would perform a check against existing values in a database to ensure that they fall within valid parameters.
For a list of addresses that includes countries outside the U.S., the state/province/territory field would need to be validated against a significantly longer list of possible values, but the basic premise is the same; the values entered must fit within a list or range of acceptable values.
Validation is particularly important, and often problematic, in the case of address information. Without an accurate and fully valid address, companies risk failed deliveries, which can lead to higher operational costs and negative customer experiences. Invalid addresses can have tax consequences as well if customer locations are assigned to the wrong jurisdiction. Poor quality address and location data can also limit an organization’s ability to enrich its data with useful geographic and demographic context.
| Data validation | Data verification | |
| Purpose | Check whether data falls within the acceptable range of values | Check data to ensure it’s accurate and consistent |
| Usually performed | When data is created or updated | When data is migrated or merged |
| Example | Checking whether user-entered ZIP code can be found | Checking that all ZIP codes in dataset are in ZIP+4 format |
Data validation isn’t just about checking values against a pre-defined list. For instance, in some cases, you might need to set limits around possible numeric values for a given field. If you are recording a person’s height, you might want to prohibit values that fall outside the expected range. If a person is listed in your database as being 12 feet tall (about 3 meters), then you can probably assume the data is incorrect. Likewise, you would not want to allow negative numbers for that field.
Fortunately, these validation checks are typically performed at the application level or the database level. For example, if you’re entering a U.S.-based shipping address into an e-commerce website, it’s unlikely that you would be able to enter a state code that is invalid for the United States. Nevertheless, other data quality issues (including inaccurate addresses) are commonplace, leading to significant data quality issues at scale.
Precisely offers address validation solutions for over 240 countries and territories worldwide. With global address and geocoding data sourced globally and updated routinely, our solutions validate your address data against authoritative external postal data sources.
EBOOK4 Keys to Improving Data Quality
It is reasonable to expect that data-driven decision making would follow the usual pattern of development and adoption: early adopters start out with centralized, carefully managed projects which eventually move into limited production. Read our ebook to learn more.
What Is Data Verification, and How Does It Differ from Validation?
Data verification, on the other hand, is quite different from data validation. Verification performs a check of the current data to ensure that it is accurate, consistent, and reflective of its intended purpose.
Verification may also happen at any time. In other words, verification may take place as part of a recurring data quality process, whereas validation typically occurs when a record is initially created or updated.
Verification plays an especially critical role when data is migrated or merged from outside data sources. Consider the case of a company that has just acquired a small competitor. The company has decided to merge the acquired competitor’s customer data into its billing system. As part of the migration process, it is important to verify that records came over properly from the source system.
Small errors in preparing data for migration can sometimes result in big problems. If a key field in the customer master record is assigned incorrectly (for example, if a range of cells in a spreadsheet was inadvertently shifted up or down when the data was being prepared), it could result in shipping addresses or outstanding invoices being assigned to the wrong customer.
Therefore, it’s important to verify the information in the destination system matches the information from the source system. This can be done by sampling data from both the source and destination systems to manually verify accuracy, or it can involve automated processes that perform full verification of the imported data, matching all of the records and flagging exceptions.
Verification As an Ongoing Process
Verification is not limited to data migration. It also plays an important role in ensuring the accuracy and consistency of corporate data over time.
Imagine that you have an existing database of consumers who have purchased your product, and you want to mail them a promotion of a new accessory to that product. Some of that customer information might be out of date, so it is worthwhile to verify the data in advance of your mailing.
By checking customer addresses against a change of address database from the postal service, you can identify customer records with outdated addresses. In many cases, you can even update the customer information as part of that process.
Identifying duplicate records is another important data verification activity. If your customer database lists the same customer three or four times, then you are likely to send them duplicate mailings. This not only costs you more money, but it also results in a negative customer experience.
To make the deduplication process more challenging, multiple records for the same customer might have been created using slightly different variations of a person’s name. Tools that use fuzzy logic to identify possible and likely matches can make the process work better.
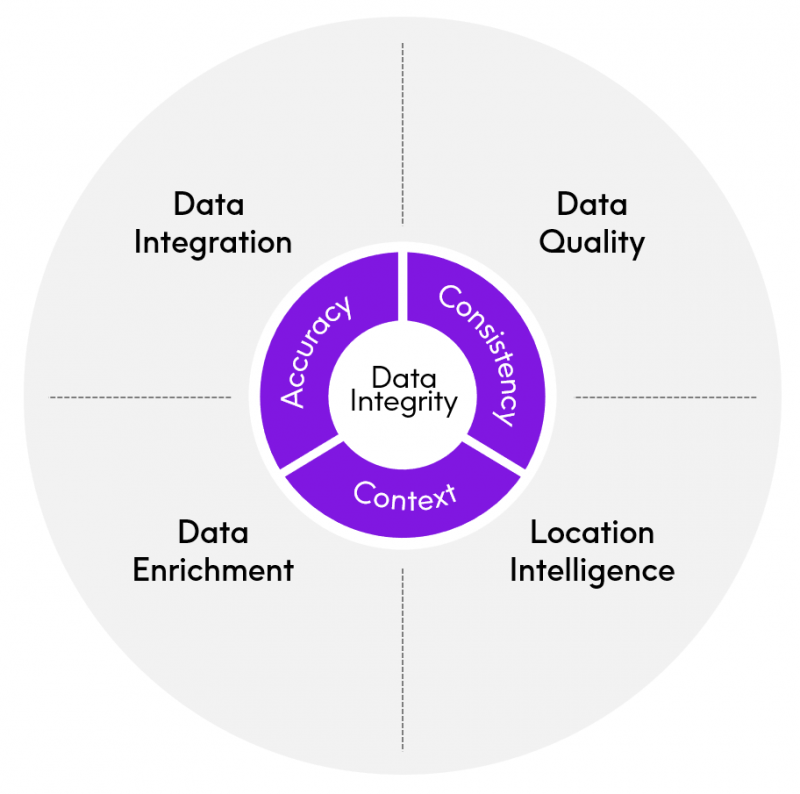
The Data Quality Mandate
More and more business leaders are coming to understand the strategic value of data in the insights that can be extracted from it using artificial intelligence/machine learning and modern business intelligence tools.
Most of those same leaders don’t fully trust their organization’s data. According to a 2023 survey by Drexel University’s LeBow College of Business, 77% of data & analytics professionals say that data-driven decision-making is a leading goal for their data programs. Yet fewer than half rate their ability to trust the data used for decision-making as “high” or “very high.”
As the volume of data increases, it’s essential that data-driven companies put proactive measures in place to monitor and manage data quality on a routine basis. Otherwise, they risk acting on insights that are based on flawed information.
Data quality is a key element within the larger domain known as data integrity. As organizations recognize the power of data as an engine of transformation, they’re looking to increase overall data integrity by using scalable AI automation tools, like those found in the Precisely Data Integrity Suite.
70% of respondents in the LeBow survey stated that data quality is the single biggest issue standing in the way of their data-driven initiatives. Leading organizations are taking the reins to proactively address that challenge.
Want to learn more? Read our eBook:
4 Keys to Improving Data Quality




