

Organizations face increasing demands for real-time processing and analysis of large volumes of data. Used by more than 75% of the Fortune 500, Apache Kafka has emerged as a powerful open source data streaming platform to meet these challenges. But harnessing and integrating Kafka’s full potential into enterprise environments can be complex. This is where Confluent steps in.
Founded by the original creators of Kafka, Confluent provides a cloud-native and complete data streaming platform available everywhere a business’s data may reside. This allows for easy development of the real-time customer experience and data-driven operations today’s world demands.
Their flagship product, Confluent Cloud, provides a 10x Kafka service built for the cloud along with 120+ connectors, stream processing, stream governance, enterprise-grade security controls, and more. Confluent Platform is a complete, enterprise-grade distribution of Kafka for on-premises and private cloud workloads.
Confluent data streams help accelerate innovation for data and analytics initiatives – but only when sourcing from data you can trust. Precisely – the global leader in data integrity and a proud Connect with Confluent program member – helps you build trust in your data to derive the insights your business users need.

With real-time update streaming, Precisely solutions make data from legacy systems like the mainframe available to Confluent and, ultimately, a wide array of targets. These high-performance solutions modernize data supply chains in organizations worldwide, for example:
- A leading international financial services organization specializing in insurance, wealth management, and retirement solutions uses Confluent and Precisely to replicate data from their mainframe in real-time users and applications across the enterprise.
- A large American financial services company specializing in retail and commercial banking, mortgages, student loans, and wealth management uses Confluent and Precisely to provide real-time data to customer channels, breaking down data silos and delivering a better customer experience.
- A Canadian financial service cooperative and one of North America’s largest federations of credit unions uses Confluent and Precisely to replicate mainframe customer data to their new mobile banking app, improving their digital customer experience and positively impacting customer retention, satisfaction, and advocacy metrics.
While digital transformation and IT infrastructure modernization projects like these look different for every organization, the need for trusted data is consistent across industries. Whether your organization’s focus is improving the customer experience, automating operations, mitigating risk, or accelerating growth and profitability, every initiative relies on data that is trusted to be accurate, consistent, and contextualized.
The Precisely Data Integrity Suite, specifically its Data Integration cloud service, breaks down legacy data silos by quickly building resilient data pipelines that connect your critical systems and data to modern data platforms to drive innovation. So, let’s look at an example workflow that uses the Data Integrity Suite to replicate mainframe data to the cloud using Confluent.
How To Start Replicating Mainframe Data in Real Time with the Precisely Data Integrity Suite and Confluent
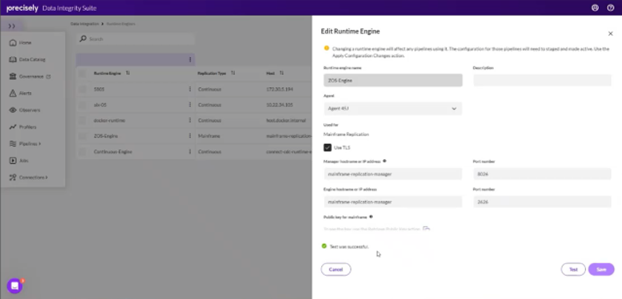
1. Configure and Verify the Runtime Engine: Ensure the runtime engine is properly configured to orchestrate communication between the cloud and the processes responsible for data movement, check the health of the mainframe replication engine, and perform a test to confirm it is up and running.
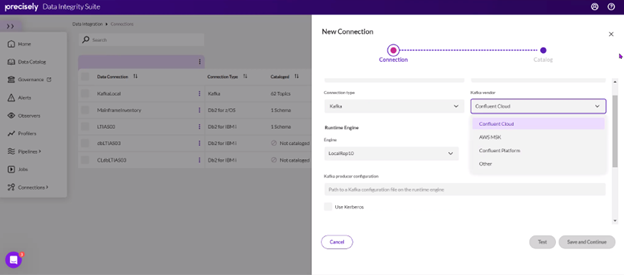
2. Build a Replication Pipeline: Create a replication pipeline within the Data Integrity Suite to replicate data from VSAM files on the mainframe to a Confluent target.
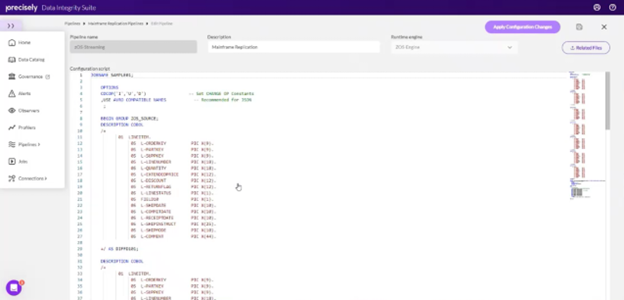
3. Customize the Replication Script: Use the scripting language provided by Precisely to define variables, specify metadata replication preferences, and map Cobol copybook descriptions for VSAM files.
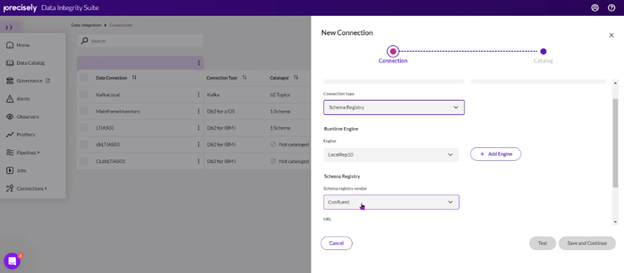
4. Configure Data Store Parameters: Specify the source and target information in the data store parameter, including connecting to Confluent running on Docker.
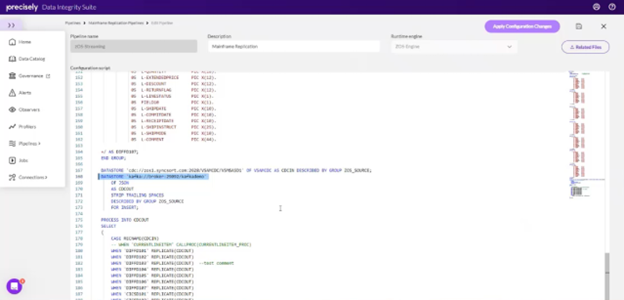
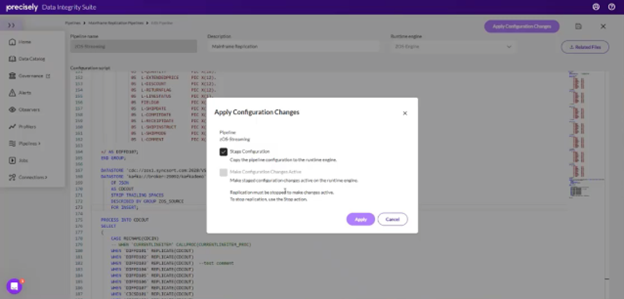
5. Apply Configuration Changes: Apply the configuration changes made to the replication script, stage them, and make them active within the environment.
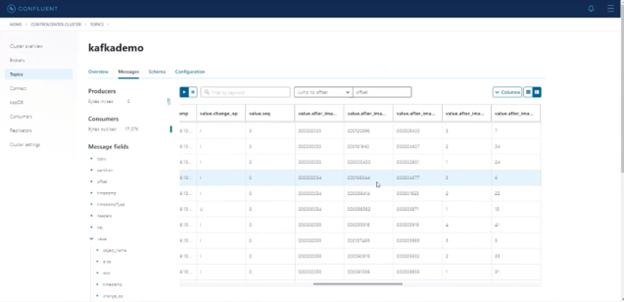
6. Monitor, Push, and Explore Data: Monitor the pipelines running, track the bytes captured, and push data from the mainframe side to see it move to Confluent. Then Use Confluent’s Control Center to browse the replicated data, view metadata, and configure additional information such as change operations and before/after images.
This workflow can effectively replicate real-time data from the mainframe to the cloud using Confluent and the Precisely Data Integrity Suite’s Data Integration service, which works within a business’s existing architecture to future-proof solutions and offer flexibility when introducing new applications and use cases.
By accelerating access to mainframe data like this, businesses can get cloud migration projects done on time and within budget, all while extending the value of mission-critical and high-investment mainframe systems. The Confluent and Precisely partnership helps make this possible and addresses the challenges of tomorrow – watch the demo now.




