

When it comes to data processing, there are more ways to do it than ever. Your choices include real-time, near real-time, and batch processing. How you do it and the tools you choose depend largely on what your purposes are for processing the data in the first place.
In many cases, you’re processing historical and archived data and time isn’t so critical. You can wait a few hours for your answer, and if necessary, a few days. Conversely, other processing tasks are crucial, and the answers need to be delivered within seconds to be of value.
Real-time, near real-time, and batch processing
| Type of data processing | When do you need it? |
|---|---|
| Real-time | When you need information processed immediately (such as at a bank ATM) |
| Near real-time | When speed is important, but you don’t need it immediately (such as producing operational intelligence) |
| Batch | When you can wait for days (or longer) for processing (Payroll is a good example.) |
What is real-time processing and when do you need it?
Real-time processing requires a continual input, constant processing, and steady output of data.
A great example of this processing is data streaming, radar systems, customer service systems, and bank ATMs, where immediate processing is crucial to make the system work properly. Spark is a great tool to use for this processing.
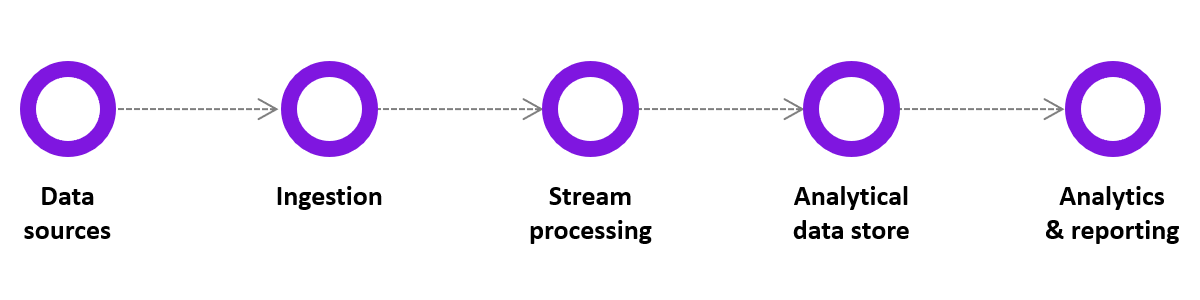
Examples of real-time processing:
- Data streaming
- Radar systems
- Customer service systems
- Bank ATMs
WHITEPAPEREasy, Automated, Real-time Data Sharing: What Can It Do For Your Business?
Learn how you can overcome the challenges to real-time, automated data sharing.
What is near real-time processing and when do you need it?
This processing is when speed is important, but processing time in minutes is acceptable in lieu of seconds.
An example of this processing is the production of operational intelligence, which is a combination of data processing and Complete Event Processing (CEP). CEP involves combining data from multiple sources in order to detect patterns. It’s useful for identifying opportunities in the data sets (such as sales leads) as well as threats (detecting an intruder in the network).
Operational intelligence, or OI, should not be confused with Operational business intelligence, or OBI, which involves the analysis of historical and archived data for strategic and planning purposes. It is not necessary to process OBI in real time or near-real time.
Examples of near real-time processing:
- Processing sensor data
- IT systems monitoring
- Financial transaction processing
What is batch processing and when do you need it?
Batch processing is even less time-sensitive. In fact, batch processing jobs can take hours, or perhaps even days.
Batch processing involves three separate processes. First, data is collected, usually over a period of time. Second, the data is processed by a separate program. Thirdly, the data is output. Examples of data entered in for analysis can include operational data, historical and archived data, data from social media, service data, etc.
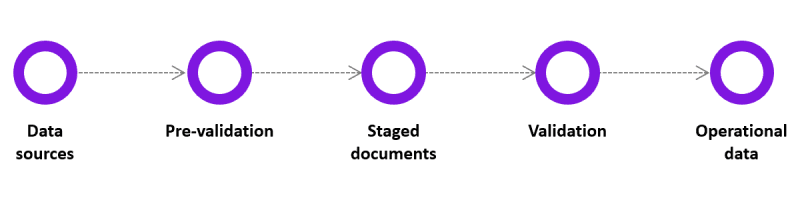
MapReduce is a useful tool for batch processing and analytics that doesn’t need to be real time or near real-time, because it is incredibly powerful.
Examples of uses for batch processing include payroll and billing activities, which usually occur on monthly cycles, and deep analytics that are not essential for fast intelligence necessary for immediate decision making.
Examples of batch processing:
- Payroll
- Billing
- Orders from customers
Precisely can help keep your data fresh. Precisely Connect continually keeps data in your analytics platforms in sync with changes made on the mainframe, so the most current information is available in the data lake for analytics.
To learn more, read our whitepaper:
Easy, Automated, Real-Time Data Sharing: What Can It Do For Your Business?




