
PartnerlösungenConfluent
Nahtlose Replikation komplexer Daten aus traditionellen Umgebungen zu Confluent über Precisely’s Datenintegrationslösungen.
Confluent und Precisely
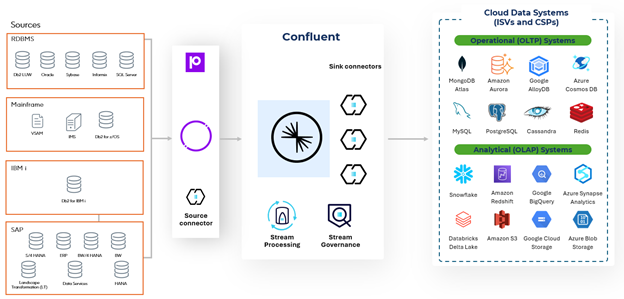
Anstatt transaktionale System-, ERP- und RDBMS-Daten auszuschließen Anstatt Transaktionssystem-, ERP- und RDBMS-Daten aus Ihren Cloud-Projekten auszuschließen, sollten Sie sich nach Datenreplikationslösungen umsehen, die alle zugrundeliegenden Komplexitäten dieser Technologien beherrschen und mit Confluent arbeiten.. With decades of expertise as a leader in mainframe sort and IBM i data availability, Precisely helps customers replicate complex data from traditional Umgebungen zu Confluent so that data can be leveraged for actionable insights. Together, Precisely and Confluent help democratize data, breakdown data silos, and solve focused business use cases wie Betrugserkennung.

Silos für den Austausch von Unternehmensdaten aufbrechen
Durch die Übertragung von Daten in die Cloud können Datensilos beseitigt, die Datenkonsistenz und -synchronisierung sichergestellt und das Daten-Sharing verbessert werden. Besteht Ihre IT-Landschaft jedoch aus Mainframe- und IBM i-Systemen, kann es Jahre dauern, bis Sie Prozesse entwickelt haben, die diese Daten in moderne Datenplattformen integrieren, um sie effizient zu teilen.
Erfahren Sie mehr über Connect!
Mit Confluent und Connect können Sie Daten aus On-Premise-Systemen integrieren und für Echtzeitanalysen in die Cloud übertragen. Connect ist darauf ausgelegt, komplexe Daten aus Plattformen wie Mainframe und IBM i in Confluent zu integrieren. Kunden konnten mit Connect und Confluent Daten aus Hunderten von Systemen integrieren und das Daten-Sharing für Geschäftsanwender aus verschiedenen Abteilungen verbessern.
Erhalten Sie Geschäftseinblicke in Echtzeit
Um verwertbare Erkenntnisse für Ihr Unternehmen zu gewinnen, müssen Sie die Leistung von Confluent Cloud und Apache Kafka nutzen, um Daten aus Ihrer gesamten IT-Infrastruktur in Echtzeit bereitzustellen. Komplizierte IT-Umgebungen und disparate Systeme können jedoch die Sichtbarkeit und den Zugriff auf wichtige Daten verhindern, so dass Datenlücken entstehen und die Zeit, die Sie benötigen, um die benötigten Erkenntnisse zu gewinnen, verlangsamt wird. Mit Connect können Sie sicherstellen, dass Sie Datenpipelines aufbauen, die Anwendungsdaten aus dem gesamten Unternehmen gemeinsam nutzen können – selbst wenn diese von einer herkömmlichen Datenbank oder Plattform wie Mainframe oder IBM i stammen.
Erfahren Sie mehr über die Connect-Funktionen zur Erfassung von Datenänderungen.
Die Funktionen von Connect zur Erfassung von Änderungsdaten helfen Ihnen, den Zugriff auf Daten schnell zu optimieren. Durch das native Verständnis von Transaktionssystemen ist Connect unerlässlich, um Mainframe- und IBM i-Daten in Confluent Cloud lesbar und verwertbar zu machen. Darüber hinaus hilft Connect bei der Erstellung von Echtzeit-Datenpipelines, die Daten von der Quelle zu Confluent Cloud replizieren, ohne dass spezielle Kenntnisse erforderlich sind.


Änderungen zur Betrugserkennung erfassen
Confluent erweitert die Betrugserkennungsfähigkeiten Ihres Unternehmens durch Echtzeit-Datenbereitstellung und Skalierung. Für eine erfolgreiche Betrugserkennung müssen jedoch Daten aus schwer zugänglichen Quellen wie Mainframe und IBM i in Confluent Cloud integriert werden.
Gemeinsam sorgen Connect und Confluent dafür, dass Ihr Unternehmen für den nächsten Anwendungsfall zur Betrugserkennung gewappnet ist. Die Echtzeit-Replikationsfunktionen von Connect für komplexe Datentypen, wie Db2/z, IMS und VSAM verbessern die in Confluent zur Betrugserkennung eingespeisten Informationen.
Erfahren Sie mehr über die Connect-Funktionen zur Erfassung von Datenänderungen.